PavLab Photos/Events
- MechE News/March2025
- 2.680 Spring 2024
- Jervis Bay 2023
- Aug 23rd 2023
- Aug 3rd 2023
- Open House 2022
- Photo Archives
Current Lab Robots
Current Projects
- MOOS-IvP
- Swarm Toolbox
- HydroMAN
- MIT Sea Beaver UUV
- USV Model Estimation
- MOOS-IvP-Multi
- Blueboat Autonomy
- Spurdog UUV
- Skywalker
- DARPA LINC
- Stochastic Ray Trace
- MTASC
- Advanced COLREGS
Current UGrad Projects


Robot Archives
Project Archives
- Swarm Declustering
- PBACS
- Prodromos
- RoboWhaler
- Autonomous Fish Finding
- Sea Train
- Multi-Arch Autonomy
- Morpheus
- HydroLink Buoy
- Perseus
- IITCHS
- Remote Explorer IV
- Aquaticus
- Charting the Charles
- Boston Harbor RoboChallenge
- COLREGS Autonomy
- ICEX 2016/2020
Maintained by: tpaine@mit.edu  Get PDF
Get PDF
moos-ivp-multi: Multi-Objective and Multi-Agent Autonomy
The moos-ivp-multi software suite is a collection of modules for distributed and decentralized decision-making in groups. There are 2.2 work years invested the core autonomy algorithms, and another 2+ work years in additional apps and behaviors that are mission specific. This page contains information about the core autonomy algorithms that have broad applicability to many missions.
The core capabilities are:

- Safety filters for emergency collision avoidance
- Decentralized network graph reconstruction and behaviors to maintain communication networks
- Decentralized combinatorial allocation of a group team members to a group of targets, or points of interest
- Scalable distributed teaming via nonlinear opinion dynamics
This toolbox leverages several approaches to model and solve problems:
- Interval Programming (the IvP in moos-ivp)
- OSQP, an open source quadratic program (QP) solver (https://osqp.org/)
- The Hungarian algorithm
- Distributed consensus and opinion dynamics algorithms
- Decentralized graph reconstruction
Safety filters for emergency collision avoidance

Figure 2.1: Eight vehicles start on the edge of a circle and must travel autonomously to the other side without hitting each other. This mission is called the joust mission and was developed in the swarm toolbox. No collision avoidance behaviors are active in this mission, only safety filtering via the pCBF app, demonstrating another layer of safety.
| Apps: | pCBF, pCollisionDetectLoockout |
| Behaviors: | None |
These apps address the need for emergency collision avoidance maneuvers that happens periodically in multi-agent missions, even when individuals are using a collision avoidance protocol such as COLREGS. There are two main causes. First, the helm solves for the best combined utility with input from all behaviors. Although individual behaviors are designed to produce rational utility functions, sometimes the additive combination of several rational utility functions can cause the solver to find a decision that is unexpected and perhaps dangerous. Secondly, control algorithms, which adjust the control inputs like thrust and rudder to move the boat towards the chosen path, can be complicated. For instance, the controller may use an integral state or low pass filter, causing vehicles to have a delayed response to newly generated desired trajectories.
For these reasons this app will filter, or adjust, the control inputs to ensure the vehicle will not collide with other vehicles. The filter is designed using the CBF method and is regularly used for our multi-agent experiments because it reduces risk and supervisor workload. The advantage of this method for filtering is that it can be used with any existing behaviors, controller, or vehicle.
The pCBF app is a derivative of the open source version https://github.com/mit-ll-trusted-autonomy/pCBF. The version in this toolbox has more features and bug fixes, including the ability to handle uncooperative (adversarial) contacts, gain schedule the control input for larger vessels, and visualization.
Decentralized network graph reconstruction and behaviors to maintain communication networks
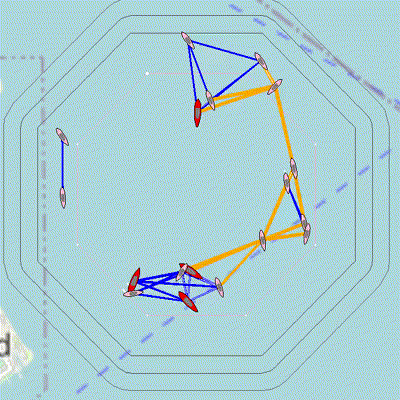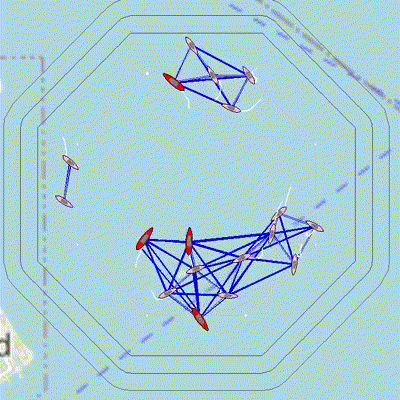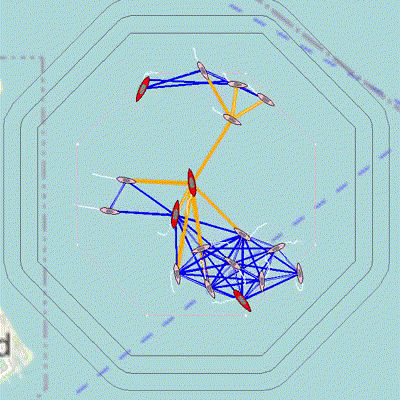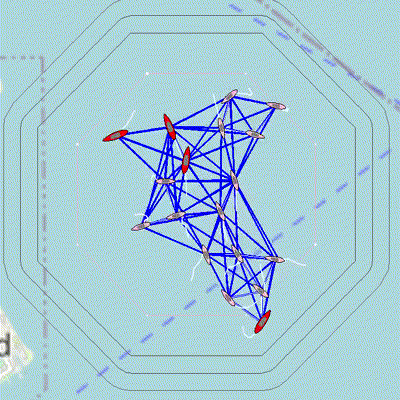
Figure 3.1: 18 vehicles use a decentralized algorithm to determine the global graph structure even though they can only communicate with local neighbors. Orange links indicate critical links as determined locally by the vehicle; these links are the only path for some vehicles to communicate with the larger group. The active network maintenance behavior, BHV_MaintainNetwork seeks to support these critical links. The collective motion of the group is governed by a flocking behavior (Boids algorithm).
| Apps: | pNetworkDiscovery, uFldNetworkEval, uNetworkViz, pFlocker, pNetworkMaintainer |
| Libs: | lib_network |
| Behaviors: | BHV_Flocking, BHV_MaintainNetwork |
These apps and behaviors were developed so that agents can recover the entire communication network structure by sharing NETWORK_REPORTS that list their neighbors, and relaying these messages from other agents.
- A decentralized algorithm in pNetworkDiscovery is used to process the information in these reports to generate the network graph structure of the full group. This app can be configured to determine the graph of only a subset of all vehicles, such the red team or the search team. The app publishes a list of all the vehicles in the graph.
- The core graph representation and message relay logic is separated into lib_network, making it possible to quickly build apps for other decentralized algorithms.
- The app uFldNetworkEval is intended to run on a central node (such as shoreside) and checks how accurately agents can reconstruct the global graph. The visualization is provided by uNetworkViz.
- The objective of BHV_MaintainNetwork is to support communication paths that are identified as critical, and this behavior works in tandem with pNetworkMaintainer.
- Collective motion is programmed via BHV_Flocking and its companion app pFlocker that uses Boids algorithm for flocking. This behavior is useful for testing the decentralized network estimation algorithms.
Decentralized combinatorial allocation of a group team members to a group of targets, or points of interest
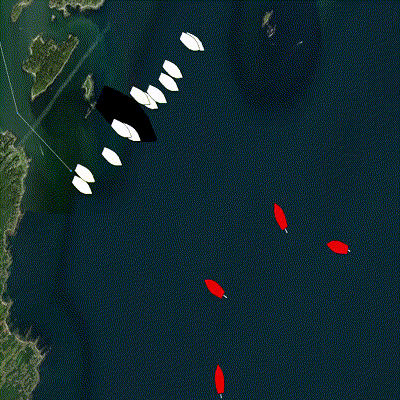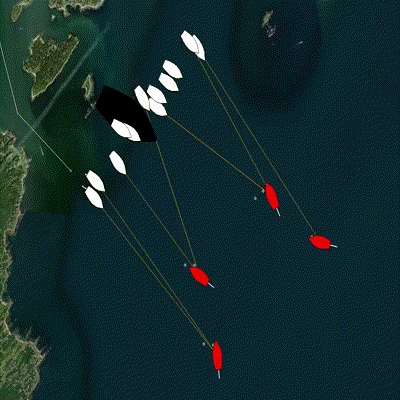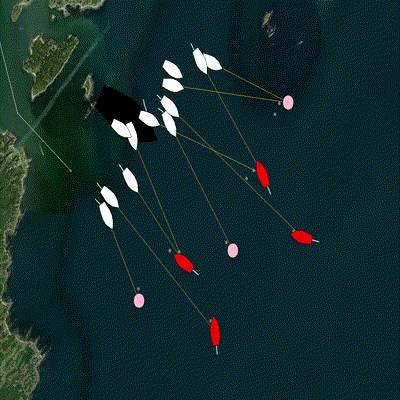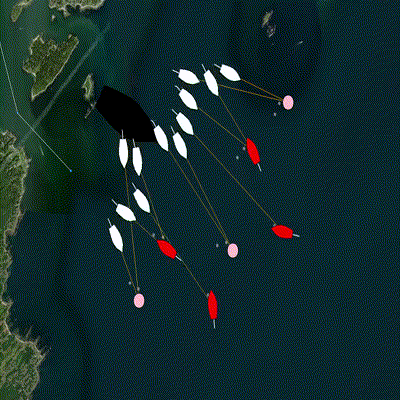
Figure 4.1: A group of defenders (white) become active one at a time and are assigned an incoming target (red) using a decentralized algorithm. The assignment is shown by the orange line, and the objective of the algorithm is to minimize the sum of the lengths of all orange lines. Additional possible target locations are selected by an operator via a mouse click and appear as pink circles. The group of defenders also allocates teammates to intercept these new target locations.
| Apps: | pGroupComboAlloc |
| Libs: | None |
| Behaviors: | Integrates with BHV_Trail (open source) |
The pGroupComboAlloc app address the problem of matching teammates to targets with the objective of minimizing total cost, such as intercept distance. The input is the list of teammates, their location, and their initial cost (like fuel level), as well as a list of targets and their location. The solver determines the best assignments and publishes the entire assignment list. In addition, pGroupComboAlloc can be configured to update a BHV_Trail behavior for collective intercepting, adjust the intercept point based on the number of teammates assigned to the target and the position of ownship in the priority queue for that target.
Scalable distributed teaming via nonlinear opinion dynamics

Figure 5.1: A group of agents continuously reach rapid distributed consensus about which of the three options (red, green, or yellow) to pursue that maximizes the collective utility. The total utility is not known known by any agent, but each agent has a local preference represented by the length of the vectors. The group uses a nonlinear opinion dynamics model to reach a consensus.

Figure 5.2: A group of agents continuously reach rapid distributed dissensus, or limited clusters of agreement, about which agents should pursue each of the three options (red, green, or yellow) to pursue that maximizes the collective utility. The total utility is not known known by any agent, but each agent has a local preference represented by the length of the vectors. The group uses a nonlinear opinion dynamics model to reach a dissensus.
| Apps: | pOpinionManager |
| Libs: | lib_opinion |
| Behaviors: | None |
The pOpinionManager runs on each vehicle and can be used to program collective decisions, usually about team assignments. Like pHelmIvP, it builds a set of options from a configuration text file, and the individual selects which option is active with input from the group. Examples of options include joining the team that is conducting a patrol, or joining the team that is intercepting (perhaps using pGroupComboAlloc to allocate teammates to targets). In this work we introduce the notion of options, typically about which team to join, that are high-level choices usually represented as the first branch in a decision-tree structure. The group collectively and autonomously decides who should pursue what option.
Example multi-agent autonomy missions with moos-ivp-multi and moos-ivp-swarm
MOOS-IvP-Multi is intended to complement the Swarm Toolbox. The two can be combined to realize more complex multi-agent autonomy. Some examples include:
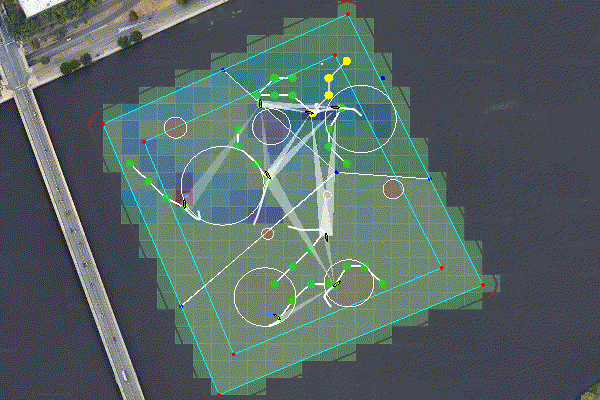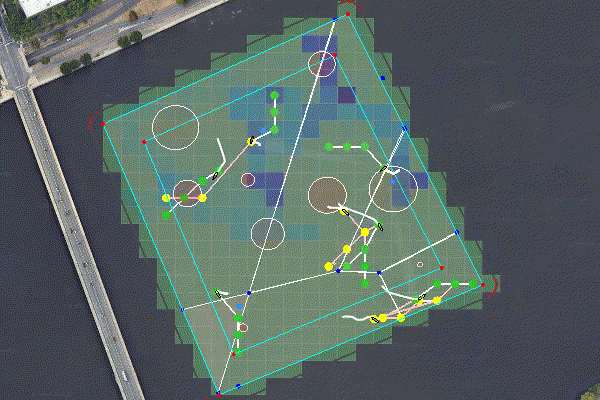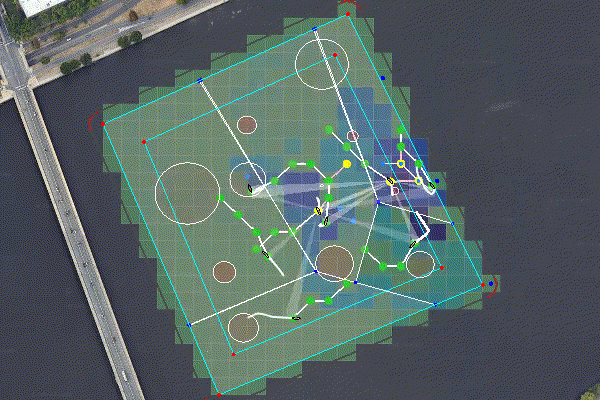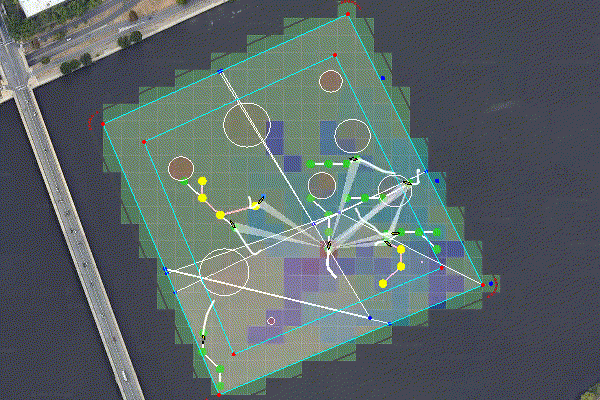
Figure 6.1: Multiple agents perform and adaptive seek and sample mission. The rosters for the seeking and sampling teams are assigned using pOpinionManager. The search space is partitioned using a BHV_Voronoi, and an optimal path is generated using an MDP with an MVI heuristic. The sample points are allocated via pGroupComboAlloc.
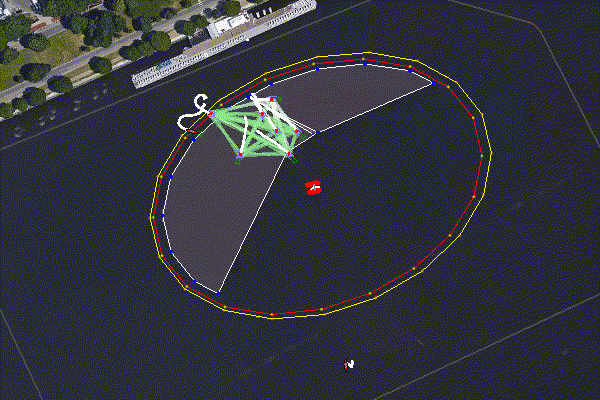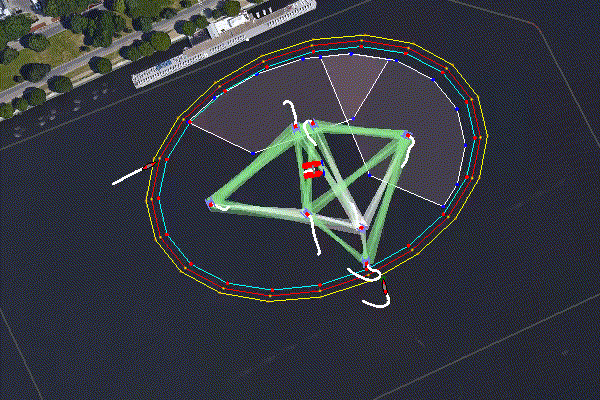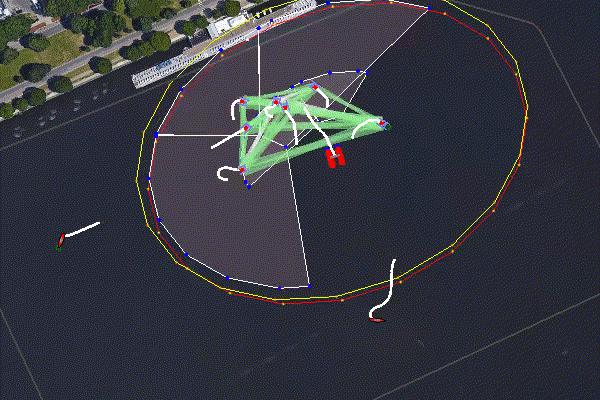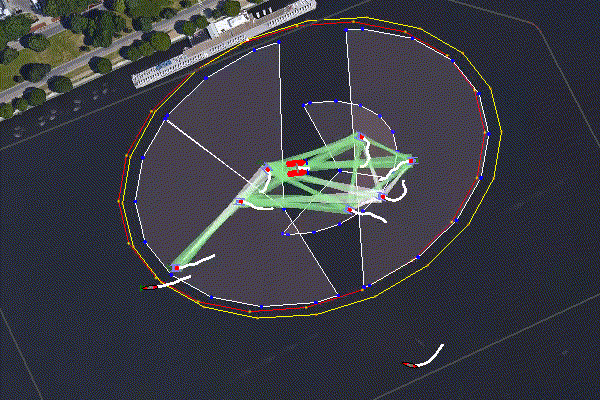
Figure 6.2: A group of defending Heron USVs defend a WAM-V high value unit (HVU) from two intruders - one was a human operated launch boat. There are two defending zones established using BHV_Voronoi, an outside patrol area, and a closer loiter region. The Herons decide as a group using pOpinionManager which of them should patrol vs loiter. When an intruder enters the patrol area a third team is formed, the interceptors, and the targets are allocated using pGroupComboAlloc. Log data from demonstration at MOOS-DAWG 23.
| Status: | Ongoing since February 2023 |
| People: | Tyler Paine |
| Robots: | https://oceanai.mit.edu/pavlab/herons, Sea Robotics SR-Surveyor M1.8 |
| Software: | MOOS-IvP public codebase, moos-ivp-multi toolbox |
Recent Publications
Document Maintained by: tpaine@mit.edu
Page built from LaTeX source using texwiki, developed at MIT. Errata to issues@moos-ivp.org. Get PDF